 |
 |
고승범님의 카프카 저서를 통해 학습한 내용을 정리하고자 한다.
카프카의 기본 구성
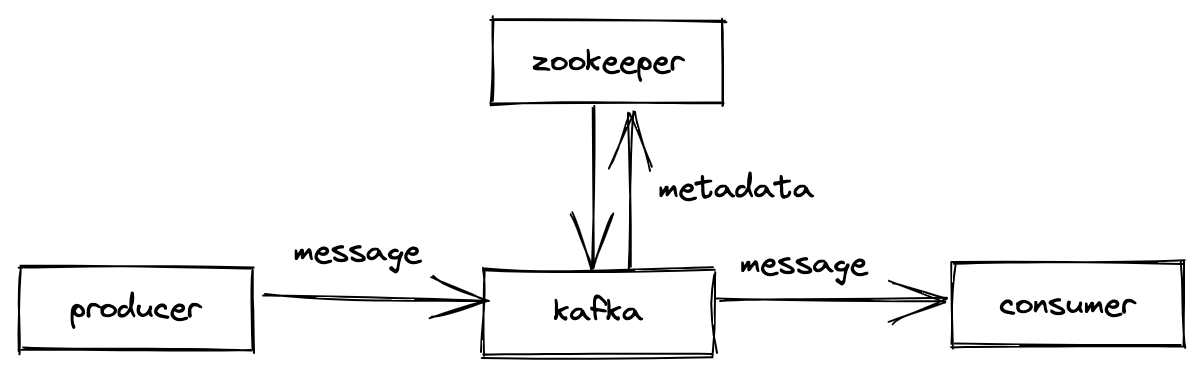
- kafka: 데이터를 받아서 전달하는 데이터 버스 역할
- producer: 카프카에 데이터를 만들어서 주는 역할을 하는 클라이언트
- consumer: 메시지를 빼내서 소비하는 역할을 하는 클라이언트
- zookeeper
- 카프카의 동작을 관리하기 위한 메타데이터를 관리하는 역할
- 브로커 정상 상태 점검 (health check) 담당
그외 카프카 주요 요소
- kafka: 브로커를 구성한 클러스터
- broker: 카프카 애플리케이션이 설치된 서버 혹은 노드
- topic:
- 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유함
- RDB의 테이블 같은 역할
- partition
- 병렬 처리 및 고성능을 위해 하나의 토픽을 여러개로 나눈 것을 말함
- RDB의 파티션 같은 역할
- segement
- 프로듀서가 전송한 실제 메시지가 로컬 디스크에 저장되는 파일
- message / record
- 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각
리플리케이션
리플리케이션이란 각 메시지들을 여러개로 복제해서, 카프카 클러스터 내 브로커들에 분산시키는 동작을 말한다. 리플리케이션 단위는 파티션이다.
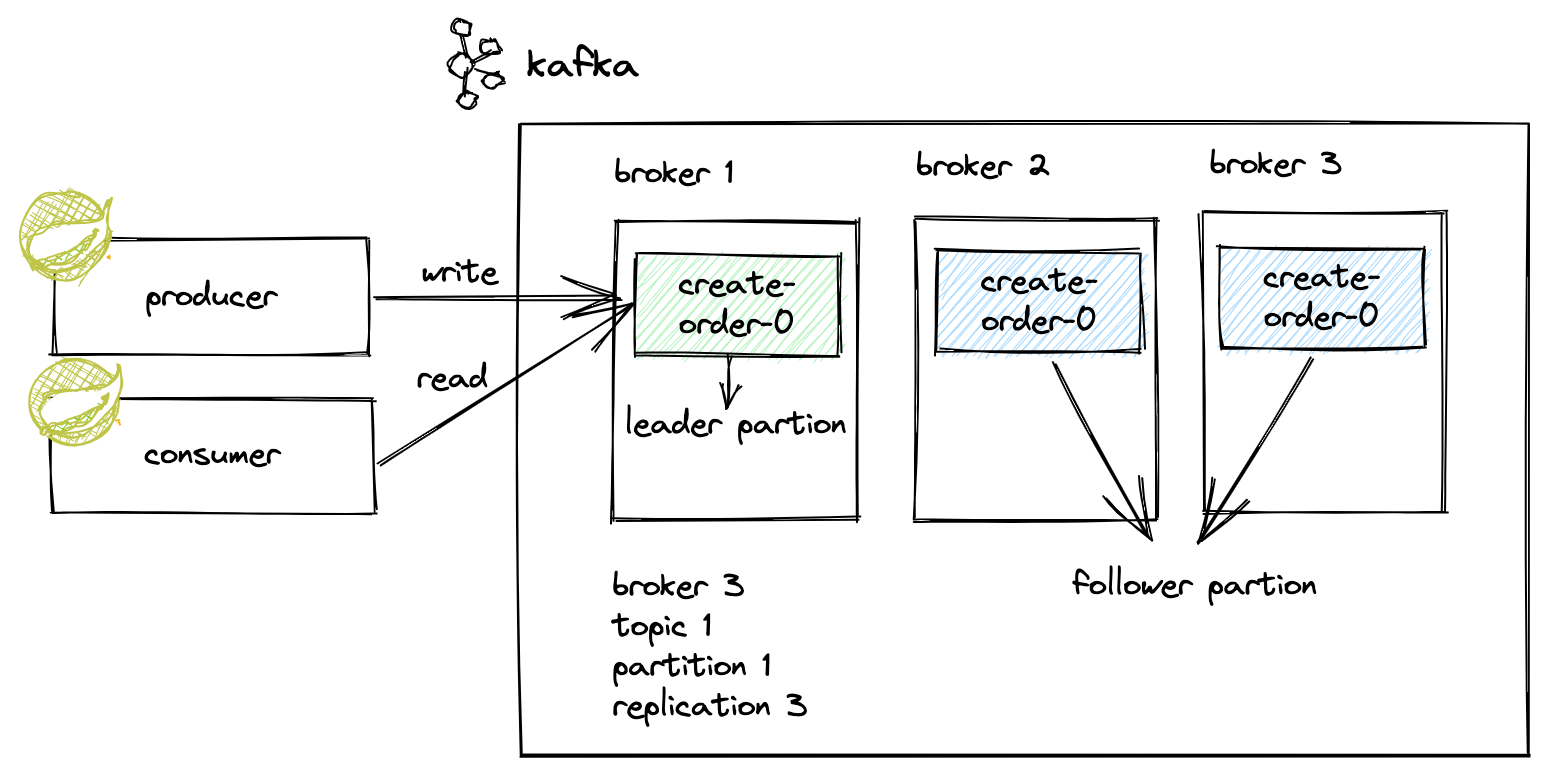
위의 그림은 다음 사례를 도식화한 것이다.
- kafka cluster: 1개
- broker: 3대로 구성
- topic: 1개
- partition: 1개
- replication factor: 3개
- create-order topic의 partition이 1개이니, 총 3개의 partition이 3대의 broker에 분산 복제된다.
- 복제수는 원본 파티션도 포함한 개수이다.
- reader partition: 1개
- producer/consumer의 읽기/쓰기는 reader partition을 통해서만 발생한다.
- follwer partition: 2개
책에서 권장하는 리플리케이션 팩터수는 다음과 같다.
- 테스트 or 개발환경: 1개
- 운영환경
- 로그성 메시지로 약간의 유실을 허용하는 경우: 2개
- 유실을 허용하지 않는 경우: 3개
- 그 이상을 설정할 수도 있지만, 저자의 경험상 3을 권장한다고 한다.
- 이 정도면 충분한 메시지 안정성을 보장하고, 디스크도 적절하게 사용한다고 한다.
<<이어서...>>
'소프트웨어-이야기 > 데이터 저장소 + 시각화 ' 카테고리의 다른 글
| Kafka Windowing (0) | 2023.07.22 |
|---|---|
| UUID와 increment PK는 언제 사용해야할까? (1) | 2022.03.12 |
| (PostgreSQL) AWS PostgreSQL RDS에 Transaction ID Wraparound 알럿 설정하기 (2) | 2021.04.04 |
| (PostgreSQL) Truncate TABLE VS delete (0) | 2021.03.28 |
| elasticsearch와 RDB 데이터 저장하기 (0) | 2019.10.23 |

