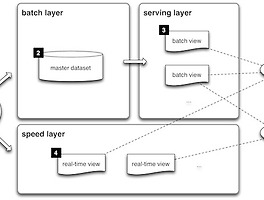
소프트웨어-이야기/데이터 저장소 + 시각화 썸네일형 리스트형 [리서치]람다 아키텍처 람다 아키텍처람다 아키텍처란 실시간성 데이터를 처리하는 스피드레이어와 지난 데이터를 다루는 배치레이어를 별도로 두어서 실시간으로 대용량 데이터를 안정적으로 관리하는 방법론이다. 람다 아키텍처 공식 사이트 람다 아키텍처의 특성 - 시스템에 문제가 있어도, 전체적인 기능은 정상적으로 작동된다. - 다양한 종류의 작업에서도 잘 작동한다. - 처리해야하는 양이 많아도 잘 버텨낸다. - 레이턴시가 짧다. - 확장성이 높다. 요 5가지 특성을 목표로 만들어진 아키텍처라고 한다. 확장성 높은 아키텍처라는 점에서 귀가 솔깃하다. @ㅂ@ 리서치를 하면서 들었던 생각많은 회사에서 람다 아키텍처를 기반으로 데이터 파이프라인을 구축했다 ( 통계 시스템 관련 자료를 찾아보면, 람다 아키텍처라는 이야기가 계속 등장한다. )그리.. [Spark]User Define Function spark에서 sql을 날릴 때, 사용자가 커스텀하게 만든 함수를 사용할 수 있게 하는 방법이 있다. SPARK의 UDFs ( User-Defined Functions ) 개념을 사용하면 된다. UDF는 우리가 피요한 새로운 컬럼 기반의 함수를 만들어준다. User Define Functions는 데이터셋을 가공해주는 Spark SQL DSL의 함수들을 확장시켜준다. 아래처럼 쓰면 된다고 한다. udf 함수에 내가 정의한 함수의 파라미터를 넘겨주면 된다. val dataset = Seq((0, "hello"), (1, "world")).toDF("id", "text") // Define a regular Scala function val upper: String => String = _.toUpperCa.. [Spark]DataFrame을 S3에 CSV으로 저장하기 S3에 Dataframe을 CSV으로 저장하는 방법 val peopleDfFile = spark.read.json("people.json") peopleDfFile.createOrReplaceTempView("people") val teenagersDf = spark.sql("SELECT name, age, address.city FROM people WHERE age >= 13 AND age [Spark] 여러개의 로그 파일 한번에 읽어오기 제플린 노트북에서 데이터 소스를 가져올 때, DataFrameReader Class를 주로 사용한다. 아래의 코드 처럼, DataFrameReader의 함수들을 사용해서 구조화되어있는 파일을 읽어들이면 DataFrame을 리턴된다. spark.read.json("s3n://jimin-bucket/a/*") spark.read.parquet("s3n://jimin-bucket/a/*") 그런데 파일을 하나하나 가져오기 보다는 여러 파일리스트를 한번에 가져오고 싶을 때가 있다.이때는 MutableList에 파일 목록들을 담아서, 이를 매개변수로 보내주면 된다. -----------------------------------------------------------------------------------.. [Spark] S3에 파일이 존재하는지 확인하기 Zeppelin 노트북에서 데이터소스를 불러올 때, AWS S3에 올려둔 파일들을 가져다가 사용한다.그런데 만약 없는 파일을 읽어들이려고 하는 경우, 에러가 발생한다.만약 일자별로 쌓인 로그 파일을 한번에 가져와서 읽을 필요성이 있다고 생각해보자. val fileList = MutableList("s3n://jimin-bucket/folder1/20170202/*", "s3n://jimin-bucket/folder1/20170203/*", "s3n://jimin-bucket/folder1/20160204/*") spark.read.json(fileList:_*) 만약 20170203 폴더에 file1이 없는 경우, 파일을 읽어들일 수 없어 에러가 난다.이런 경우, fileList 변수에는 실제로 존재하는.. [Spark]DataFrame을 Parquet으로 저장하기 http://spark.apache.org/docs/latest/sql-programming-guide.html 파케이파일로 데이터프레임이 저장되면, 스키마 정보를 유지한 채로 데이터를 저장할 수 있다.위의 코드 예시를 보면, 데이터프레임을 파케이로 저장한 후 => 해당 파케이파일을 읽어들이면 스키마를 유지하고 있어 TempVIew를 생성할 수 있다. [couchbase]카우치 베이스에서 테이블이란? 카우치베이스와 RDB의 논리적 개념 차이에 대해서 헷갈려서, 찾아봤다. 카우치베이스의 bucket은 RDB의 database의 개념과 유사하다고 한다. 그러면 카우치베이스의 table의 개념은 무엇일까 궁금했다. 카우치베이스에서는 별도의 TABLE이 없다. 때문에 document에 type이라는 속성을 추가해서, 유사한 데이터를 묶어서 관리해주어야 한다. 참고 : http://blog.couchbase.com/10-things-developers-should-know-about-couchbase 위는 카우치베이스 사용할 때 알아야하는 10가지에 대한 포스팅의 캡쳐 이미지이다. 하나의 버킷은 RDBMS에서 database로 볼 수 있다. 때문에 다른 속성을 가진 도큐먼트여도 같은 버킷에 저장되어야 한다. .. [카우치베이스]Insert와 Select의 시간차 금일 과제를 진행하면서 카우치베이스에서 Insert를 하고난 직후에 Select를 하면 Insert했던 값이 반영이 안되는 이슈가 있었다. 왜 그럴까? 이유를 확인한다면 이걸 수정하려면 어떻게 해야할까? 궁금했다. 왜 그럴까?1. insert의 메모리 객체 반영론카우치베이스의 Insert 메서드(add)는 데이터가 디스크에 완전히 반영되기 전에 메모리 객체에 반영되고 나면 성공 메시지를 되돌려 준다. 입력된 데이터는 디스크에 저장되고, 이 데이터가 다시 복제 설정된 개수만큼 다른 노드로 복사되게 된다. >즉, 디스크에 값이 저장되기 전에 true를 리턴해줘서, select를 할 때 직전에 insert 한 값이 바로 반영이 안되었던 거다. (그렇다면 select는 디스크에 직접 접근해서 계산해온다는 거겠지.. 이전 1 ··· 3 4 5 6 7 다음