본 글에서는 Amazon RDS for PostgreSQL에서 transaction ID의 상태를 모니터링하는 방법과 주요 문제를 해결하는 일반적인 방법에 대해서 설명하고자 한다. 이 글은 AWS Database blog에 포스팅된 Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL 을 번역하여 정리한 글이다.
transaction ID란?
PostgreSQL은 vacuum 없이 21억여 개의 트랜잭션까지 처리할 수 있다. 만약 vacuum 없이 처리된 트랜잭션의 수가 2^31 - 10,000,000에 도달하게 되면, Postgresql은 베큠이 필요하다는 로그를 남기기 시작한다. 그리고 (2^31 - 1,000,000)에 도달하면, PostgreSQL은 Read-only 모드로 설정되고, 오프라인, 단일 유저, standalone vacuum 모드가 된다. 이렇게 되면 vacuum은 데이터 크기에 따라 몇 시간에서 며칠간의 데이터베이스 다운타임을 일으키게 된다.
가용할 수 있는 transaction ID 수가 20억개를 넘어가는 경우, transaction ID가 다시 첫 번째 순서로 로테이션할 수 있도록 처리해줘야 한다. 이를 transaction ID wraparound라고 하며, vacuum에서 이러한 역할을 담당하고 있다.
🔎 Early warning is the key
PostgreSQL Database에서 Transction ID가 21억 개가 된다는 것은 "세상이 끝나는 시점"과도 같다.
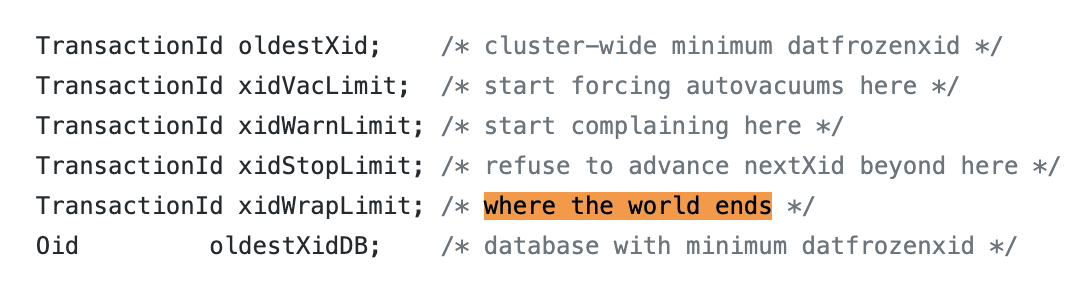
PostgreSQL 소스코드에도 where the world ends라는 코멘트가 달려있다.
https://github.com/postgres/postgres/blob/master/src/include/access/transam.h#L219
트랜잭션 아이디가 오래된 값을 유지하게 되는 경우, Amazon CloudWatch 지표인 MaximumUsedTransactionIDs를 사용하여 경고를 받을 수 있다.
이 지표를 만들기 위하여 Amazon RDS Agent는 다음과 같은 쿼리를 실행한다.
SELECT max(age(datfrozenxid)) FROM pg_database;AWS Console > CloudWatch > Alarm에서 다음과 같이 알럿을 설정할 수 있다.
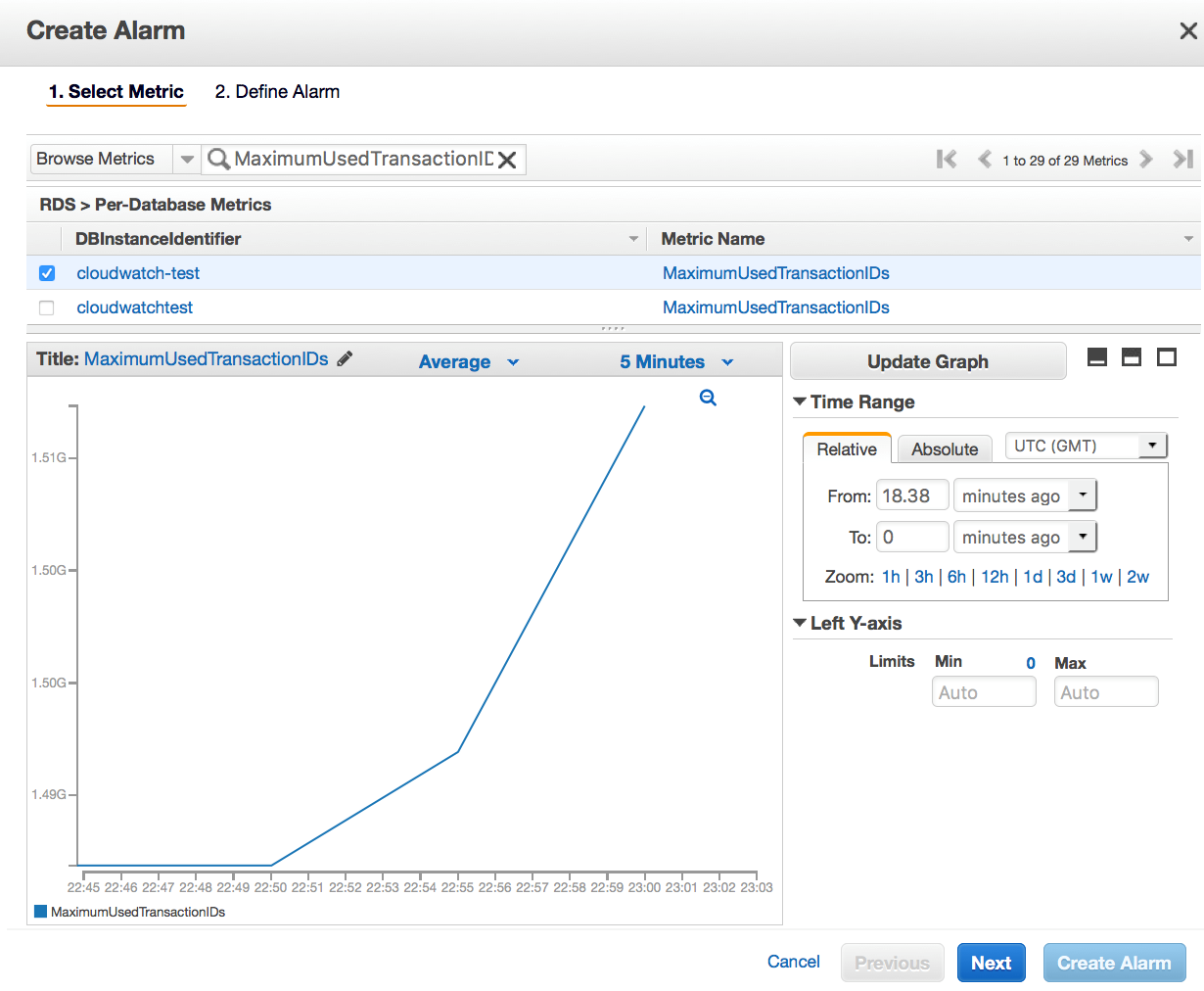

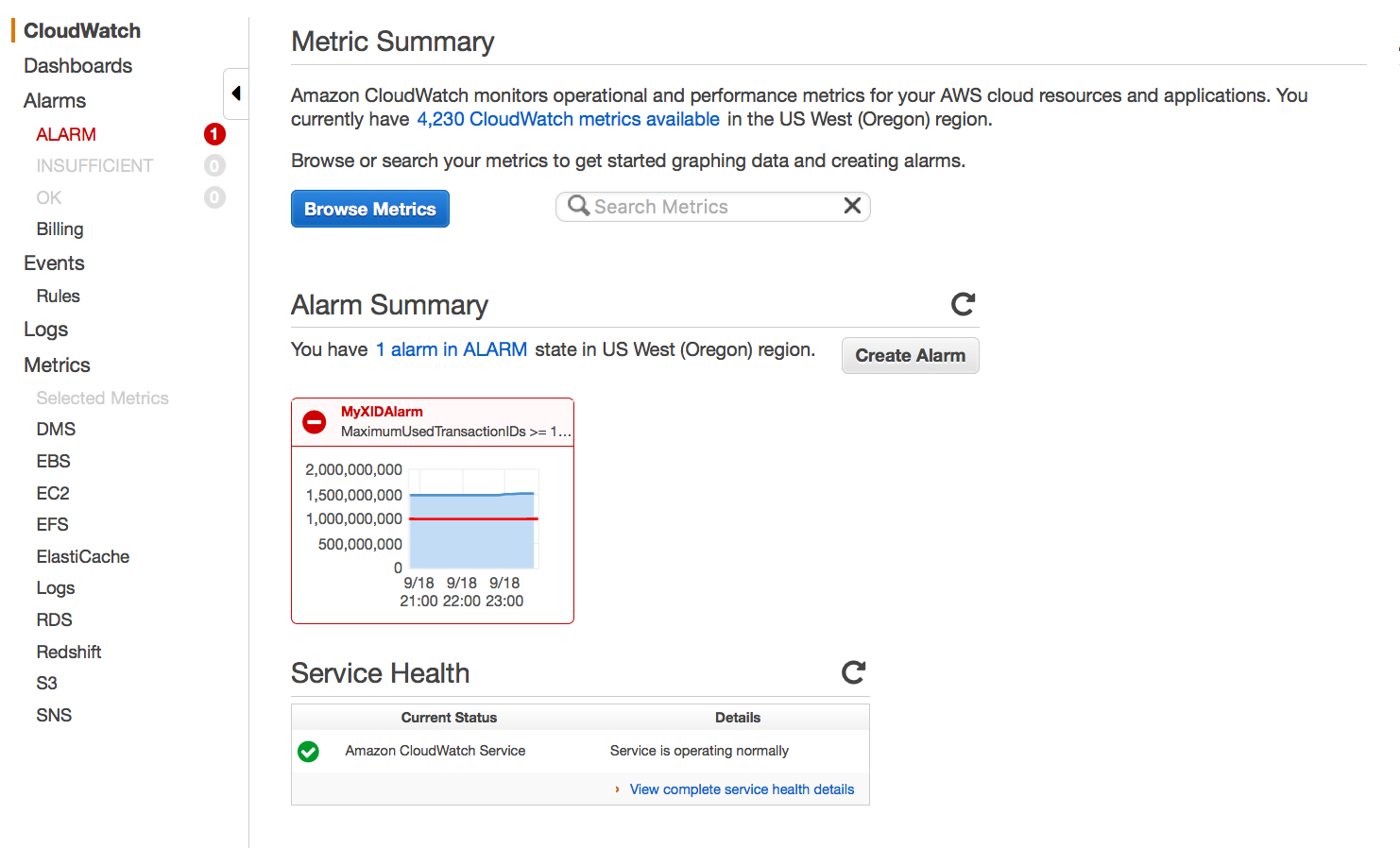
글의 저자의 경험상 알럿의 수치로 10억을 권장한다고 한다. 그러나 때로는 500만으로 설정하는 게 유용한 경우도 있다고 한다.
Transaction ID의 나이가 10억인 경우, 문제의 원인을 찾는 데에 시간이 충분할 수 있다. 그런데 문제를 해결하는 데에 필요한 시간은 원인에 따라 달라진다.
transaction ID wraparound를 방지하기 위하여 autovacuum을 실행하는 기준점이 되는 autovacuum_freeze_max_age는 기본 값이 2억이다. Transaction ID가 10억까지 올랐다는 것은 autovacuum이 정상적으로 동작하지 않는 문제가 있다는 것을 의미한다.
이미 문제가 있는 상황인데 Transaction ID가 10억이 될 때까지 문제를 인지하는 시기를 지체시키는 것은 문제를 처리할 수 있는 시간을 단축시키는 것이기 때문에 비효율적이다. 그래서 이를 좀 더 빨리 인지할 수 있는 트리거가 필요하다.
🚨 The monitor has sent an alarm—now what?
경고 알럿을 받은 후, 문제의 솔루션을 찾기 위해 필요한 단계에 대해서 설명하고자 한다.
문제의 원인을 파악한 후에는 verbose vacuum을 실행하여 작업에 걸리는 시간을 확인하는 것이 좋다. 이는 문제를 즉시 해결하고, 장기적인 개선 방향을 수립하는 데에 도움을 준다.
경고 알럿을 받은 후, 확인해야하는 수치는 3가지이다.
- autovacuum을 실행중인 세션
- 데이터베이스 Transaction ID 나이
- 테이블의 Transaction ID 나이
이 세가지 값을 알면, 문제 현상을 파악하는 작업을 시작할 수 있다.
🧹 autovacuum을 실행 중인 세션
autovacuum이 실행중인 세션은 다음 쿼리를 사용하여 확인할 수 있다.
SELECT datname, usename, pid, current_timestamp - xact_start AS xact_runtime, query
FROM pg_stat_activity
WHERE upper(query) like '%VACUUM%'
ORDER BY xact_start;👵🏻 데이터베이스 Transaction ID 나이
SELECT datname, age(datfrozenxid) FROM pg_database ORDER BY 2 DESC LIMIT 20;👵🏻 테이블의 Transaction ID 나이
아래의 쿼리는 가장 오래된 상위 20개 테이블을 조회하는 쿼리이다. 대부분 가장 상위에 있는 테이블이 autovacuum이 작동하는 테이블이다.
SELECT c.oid::regclass as table_name, greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age, pg_size_pretty(pg_table_size(c.oid)) as table_size
FROM pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE c.relkind = 'r'
ORDER BY 2 DESC LIMIT 20;Autovacuum 문제 사례
이다음에는 autovacuum의 문제 사례 2가지를 설명하고자 한다. 이를 토해 위에서 설명한 쿼리 결과를 바탕으로 문제를 분석하는 방법을 설명하고자 한다.
(1) autovacuum 세션이 오랫동안 지속되는 경우
첫 번째 사례는 autovacuum 세션이 너무 오랜 시간 동안 실행되는 상황이다. 보통 이 경우는 maintenance_work_mem 설정값이 너무 작게 설정되어있어서 발생한다.

maintenance_work_mem은 VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY 같은 명령문 실행에 사용되는 메모리 크기를 의미한다. autovacuum_work_mem은 autovacuum에서 사용하는 메모리를 지정할 때 사용된다. autovacuum_work_mem이 설정되어있는 경우 maintenance_work_mem이 아니라 autovacuum_work_mem 값을 사용한다.
그럼에도 세션이 오랜시간 지속되는 경우, 대량의 데이터가 적재되는 테이블을 대상으로 autovacuum 설정 튜닝이 필요하다.
이는 autovacuum이 특정 테이블에서만 적극적으로 활성화되도록 설정할 수 있다는 장점이 있다.
utovacuum_vacuum_cost_delay의 기본값은 20ms이다. 대량의 테이블에서는 autovacuum을 좀 더 길게 설정하는 게 좋다.
이는 다음과 같은 명령문으로 설정할 수 있다.
ALTER TABLE mytable SET (autovacuum_vacuum_cost_delay=0);(2) autovacuum 세션이 완료된 것처럼 보이지만, 처리량이 더딘 경우
autovacuum 세션이 완료된 것처럼 보이지만 실제 처리량이 떨어지는 경우에는 문제를 해결하기가 좀 더 어렵다.
기본적으로 autovacuum_max_workers은 3으로 설정된다. 이는 autovacuum을 각 테이블에 동시에 실행하는 worker의 수를 의미한다. 보통 이 수치는 일반적으로 적당한 값이다. 그러나 테이블 수가 3만 건 이상이 될 정도로 많은 경우에는 개수를 좀 더 늘리는 게 좋다.
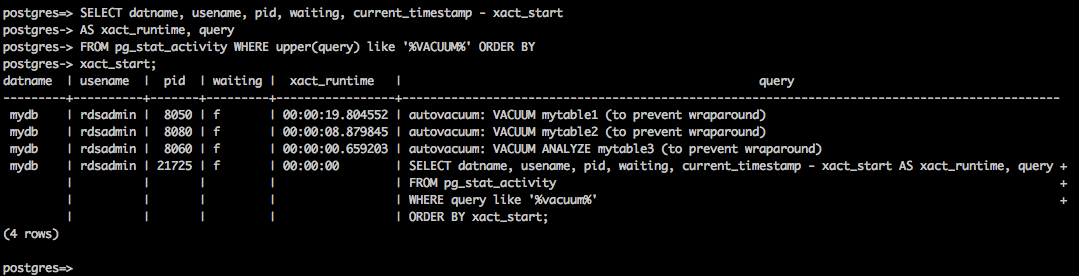
위는 현재 실행중이 autovacuum 세션을 조회했을 때, 나오는 결과 예시이다. 위의 샘플 결과를 살펴봤을 때, autovacuum이 문제를 일으키지 않는 걸로 보인다. 세션이 오랫동안 실행되고 있지도 않고, 3개의 테이블에서 vacuum이 실행되고 있기 때문이다.
그런데 데이터베이스의 수명인 transaction id의 나이가 알럿으로 설정한 임계값인 10억을 초과했다는 알림을 받게 될 수도 있다. 이는 autovacuum은 계속 실행되고 있으나, 처리량이 더딘 상황으로 볼 수 있다.

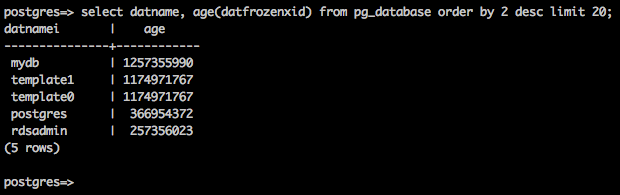
이때에는 데이터베이스와 테이블의 나이를 확인해보면, autovacuum을 방해하는 요소가 있음을 유추할 수 있다.
이 사례에서는 autovacuum이 실행되어야 하는 테이블의 수를 확인해보았다.
SELECT count(*) FROM pg_tables;
조회 결과, 테이블의 수가 10만건이 넘었다. autovacuum 워커 수는 기본적으로 3개인데, 워커의 수 대비 처리해야 하는 테이블의 수가 많다고 볼 수 있다.
때문에 이 경우에는 autovacuum_max_workers값을 늘려야한다.
이때, 두 가지를 유의해야 한다. auto_vacuum_cost_limit가 활성화된 워커에 고르게 배분되고, 각 워커에 maintenance_work_mem에 정의한 만큼 메모리가 할당된다는 점이다.
이 글의 작성자는 다음과 같이 autovacuum 옵션을 설정하여, 트랜잭션의 나이가 줄어드는지 검토하기를 제안한다. 그리고 테이블 설계를 개선하여, 전체 테이블 수를 줄일 수는 없는지 검토해볼 것을 제안한다.
autovacuum_max_workers = 6
auto_vacuum_cost_limit = 1500
maintenance_work_mem = RDS default🎸 기타 Tip - 로그 살펴보기
CloudWatch 지표뿐만 아니라, autovacuum의 로깅을 활성화하여 autovacuum이 오래 지속되는 테이블을 살펴보는 것이 좋다. ( force_autovacuum_logging_level , log_autovacuum_min_duration )
🎸 기타 Tip - 수동 vacuum 실행하기
테이블의 나이가 20억에 가까워진 테이블을 대상으로 직접 vacuum을 실행하는 것이 문제를 해결하는 데에 도움이 될 수 있다. 이때, verbose 키워드를 사용하면 vacuum을 실행할 때 어떤 상황이 벌어지고 있는지 확인할 수 있다.
예를 들어, 사용하지 않는 index 때문에 vacuum 실행이 지연되고 있다면, 해당 index를 제거함으로써 vacuum의 처리 효율을 높일 수 있다.
원글
- https://aws.amazon.com/ko/blogs/database/implement-an-early-warning-system-for-transaction-id-wraparound-in-amazon-rds-for-postgresql/
- https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Appendix.PostgreSQL.CommonDBATasks.Autovacuum.html
- https://aws.amazon.com/ko/blogs/database/understanding-autovacuum-in-amazon-rds-for-postgresql-environments/
'소프트웨어-이야기 > 데이터 저장소 + 시각화 ' 카테고리의 다른 글
| Kafka Windowing (0) | 2023.07.22 |
|---|---|
| [키설계] UUID와 increment PK는 언제 사용해야할까? (1) | 2022.03.12 |
| (PostgreSQL) Truncate TABLE VS delete (0) | 2021.03.28 |
| elasticsearch와 RDB 데이터 저장하기 (0) | 2019.10.23 |
| (PostgreSQL) Array Field 인덱스를 사용할 때 고려할 점 (0) | 2019.09.28 |

