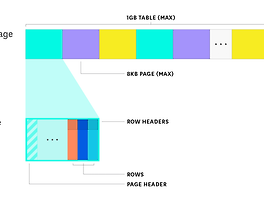
최근, PostgreSQL의 Array 데이터 타입을 사용하자는 설계 아이디어를 검증하기 위해 찾아본 자료를 정리해보고자 한다.
간단히 요약하자면, Array 데이터 타입에 인덱스를 추가하는 것은 잘못된 설계가 될 수 있다는 점이다 😳
배경
- 최근에 게시물에 태그를 추가하고, 태그로 게시물을 조회하는 기능을 구현해야했다.
- 게시물에 추가된 태그는 저장된 순서 그대로 조회가 가능해야했다.
아이디어
위의 기능을 위해 "게시물에 저장된 태그를 Array 데이터 타입"으로 저장하자는 아이디어가 제안되었다.
Array 타입에 인덱스를 추가하는 것에 호의적이였던 이유
PostgreSQL의 Array 데이터 타입을 사용하자는 아이디어는 아래와 같은 편의성 때문이였다.
1. 태그 목록을 저장하고, 읽기가 용이하다.
게시물에 추가된 태그 목록에 순서가 있는 경우, 애플리케이션은 각 태그의 우선순위를 고려하여 데이터를 저장해야한다.
그러나 Array 데이터 타입을 활용하는 경우, 클라이언트에서 전달해준 순서 그대로 태그 목록을 Array 컬럼에 저장하면 된다.
그래서 데이터를 내려줄 때에도 우선순위를 신경쓰지 않아도 되고, 태그 목록을 조회하기 위해 쿼리를 더 호출하지 않아도 된다.
2. Django에서도 PostgreSQL의 Array 데이터 타입을 편하게 조작할 수 있는 인터페이스를 제공한다.
>> Post.objects.create(name='First post', tags=['thoughts', 'django'])
>> Post.objects.filter(tags__contains=['thoughts'])
<QuerySet [<Post: First post>]>
3. Array에 GIN 인덱스를 추가할 수 있다.
얼핏 보기에 Array 데이터 타입에 인덱스를 추가하면, 디스크 사용량도 높고 성능도 떨어질 것 같았다. 그냥 찝찝했다.
그런데 누군가 Array 데이터 타입에 대한 성능 비교글을 올린 것을 확인하니, 태깅을 관계형 테이블에 저장하는 방식과 큰 차이가 없었다.
( 참고글 : Tag all the Things, part 2 )
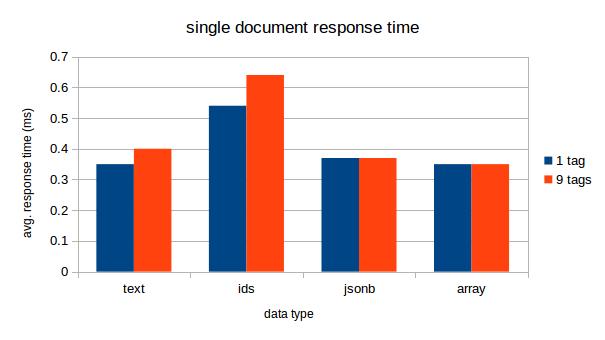
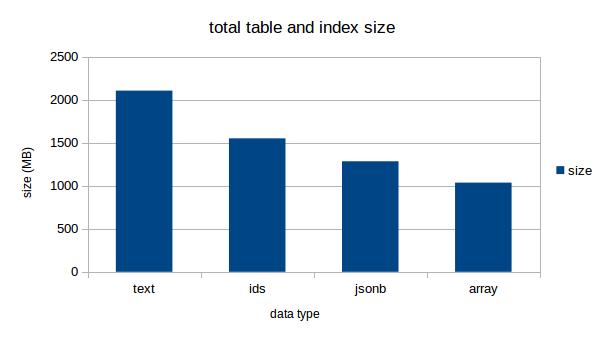
그러나 총 카운트 수를 구하는 쿼리는 텍스트 데이터 타입만큼 빠르지는 못하다. ( 참고 - Tag all the Things, part 3 )
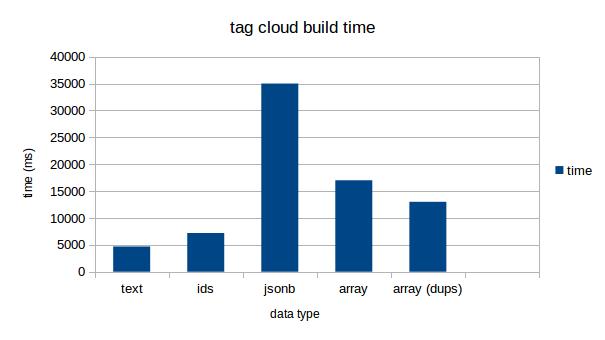
총 카운트 수를 구하는 쿼리를 사용하지 않는다면, Array 데이터 타입이 꽤 쓸만해보였다.
*기타 팁* Array 데이터 타입 쿼리인 ANY 함수는 사용하면 안된다. 이 함수는 인덱스를 사용하지 않기 때문에 퍼포먼스가 떨어진다.
그럼에도 인덱스가 필요한 Array 데이터 타입을 사용하지 않은 이유
PostgreSQL Array Data 활용 가이드 문서를 보면, 아래와 같은 팁이 있다.

Array에 있는 데이터를 조회하는건, 안좋은 설계의 신호라고 한다. 검색하기도 어렵고, Array 요소들을 확장하기도 어렵다고 한다.
그래서 Array 데이터 타입과 인덱스에 관하여 조사하다보면, 이렇게 사용하지 말라는 내용들이 나온다.
왜 잘못된 설계인건지 사례를 생각해보면 좀 와닿는다.
1. 검색이 어렵다
예를 들어 태그명에 LIKE 검색이 필요한 경우, Array 데이터의 GIN 인덱스를 활용하기 어렵다. LIKE 검색이 필요했기 때문에 우리팀은 Array 데이터 타입을 사용하지 않기로했다.
2. 확장이 어렵다
게시물에 속한 태그가 많아지는 경우, 게시물 단일 정보만 조회하는 로직의 비용이 커질 수 있다. ( 메모리 이슈 등 )
때문에 태그 갯수에 대한 제한이 생긴다.
결론
검색이 필요한 경우에는 Array 데이터 타입을 사용하지말자.
배열의 크기가 큰 데이터는 Array 타입에 저장하지 말자.
끝~
'소프트웨어-이야기 > 데이터 저장소 + 시각화 ' 카테고리의 다른 글
| (PostgreSQL) Truncate TABLE VS delete (0) | 2021.03.28 |
|---|---|
| elasticsearch와 RDB 데이터 저장하기 (0) | 2019.10.23 |
| (PostgreSQL) PostgreSQL Client Tool 비교하기 (3) | 2019.04.13 |
| (PostgreSQL) BRIN 인덱스 활용하기 (2) | 2019.03.10 |
| (PostgreSQL) 쿼리 실행계획 비쥬얼라이징하기 (0) | 2019.02.17 |